2023-12_usb-real-data-rates.md
2023 12 12
I've been trying to sort out how to get enough data out of the NIST printer to get to the "millisecond benchy" goal - part of that is figuring what real underlying data rates on USB serial links are.
To start, I spun up some max-rate-ingestion tests, on ubuntu and windows,

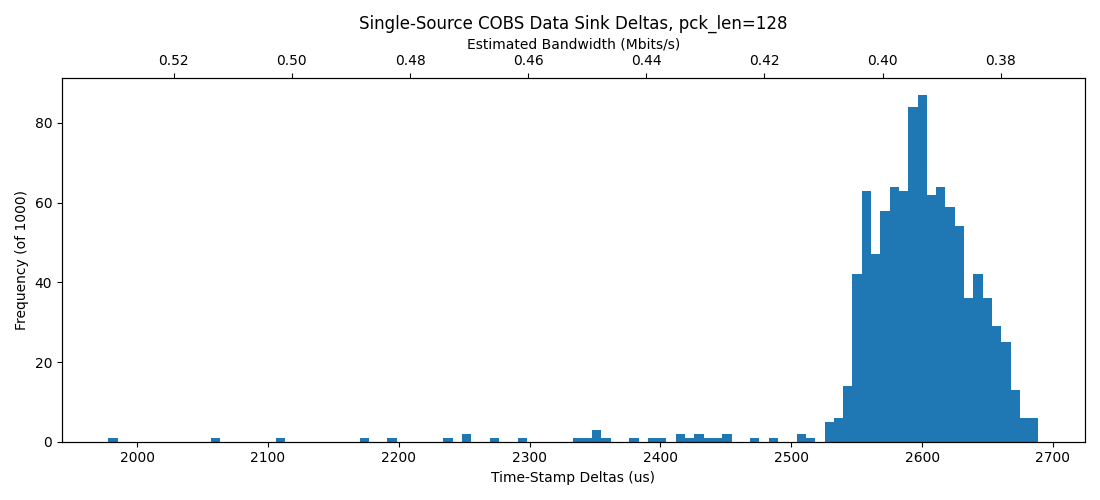

So, we learn that there's no real change to the underlying data rate with increasing packet sizes, and we also learn that windows and ubuntu are not actually so different:
Warning the data in the table below are faulty (bad Mbits/s plotting and overclocked RP2040 reporting speedier deltas than were real), but they serve to show the relative performance:
Windows |
Ubuntu |
|---|---|
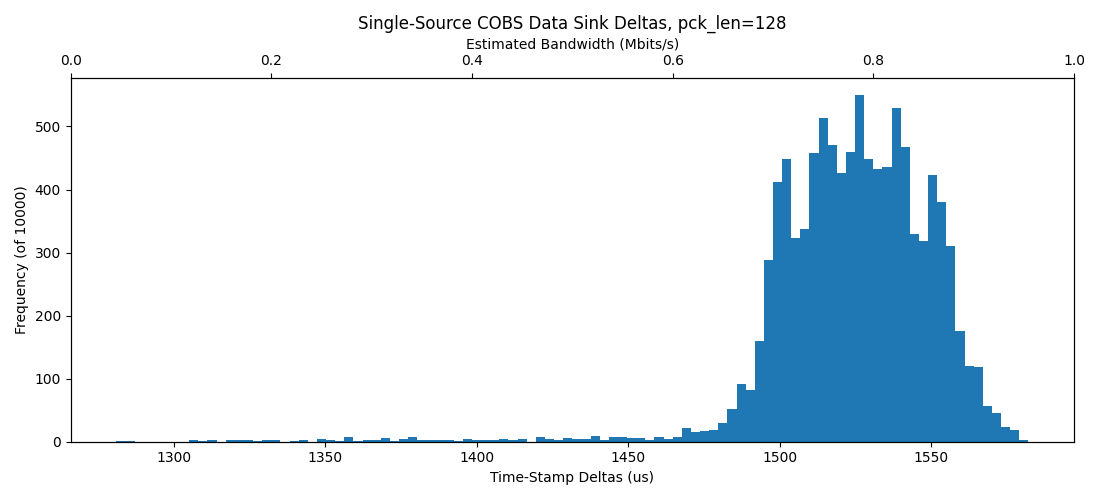 |
 |
Ubuntu packets are arriving a little more spaced out than in windows - but, also, the ubuntu machine (a Lattitude 5490) was under-spec'd relatively to the windows machine (XPS 15 2019).
Surprisingly...
Windows out performs ubuntu here. Now, there is a big difference in machines as well: the Windows platform is a much faster machine. However, not starkly so, and I had been expecting a noticable bump in perf from Unix. Fortunately for me, this is not the case.
We do also win some total bandwidth when we use bigger packet sizes, sort of as expected.
But we have a clear cap near 0.5 Mbit/sec in terms of real performance, which FWIW is 1/24th of the USB 2.0 Full-Speed-Device reported max, so there's clearly a lot missing here. Our data-printer spec asks for about 4Mbit/sec, which is also worrying: we would need to have up to five of these devices to make that possible, and have them each working in parallel.
Other Externalities
This is also not accounting for i.e. multiple devices, flow control, flow going down (as well as up), etc. For that I will have to improve the system / etc.
This also doesn't properly inspect whether / not there is significant performance dings due to i.e. cobs, which is some looping python, anyways - so, maybe there is real evidence that we want to i.e. ethernet to the first thing, etc.
2023 12 21
So, we want to... consume and produce data, as fast as possible in either direction, and open multiple ports.
I think that the multiple ports thing is going to teach me what I want to know about asyncio, and is simple enough that I can try to replicate it with multiprocessing as well.
... we're into that, we just need to run 'em both and plot two-ups, this should be simple next step, then compare to multiprocessing !
2023 12 27
OK, first let's test multi-sink using blocking codes. I'll modify the original to not "read-until" but instead consume bytes at a time, then simply open two devices and develop another plot.
Multi-Device, Blocking
OK: current tech, here's one device with ye old' blocking code:

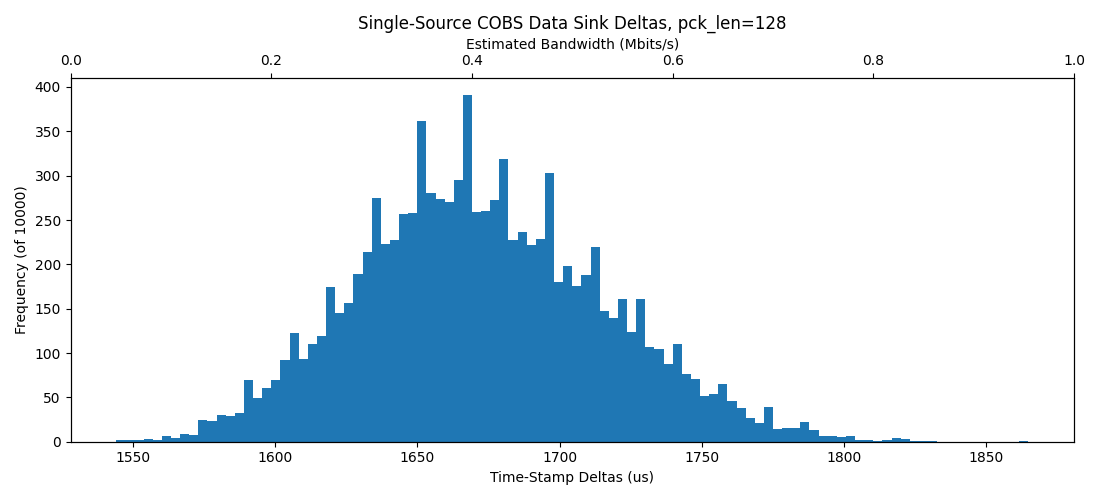
Now let's get two up, using this blocking code, no hub:
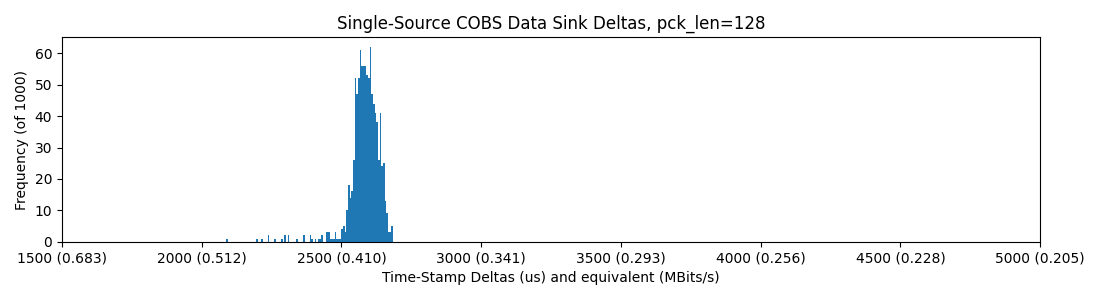
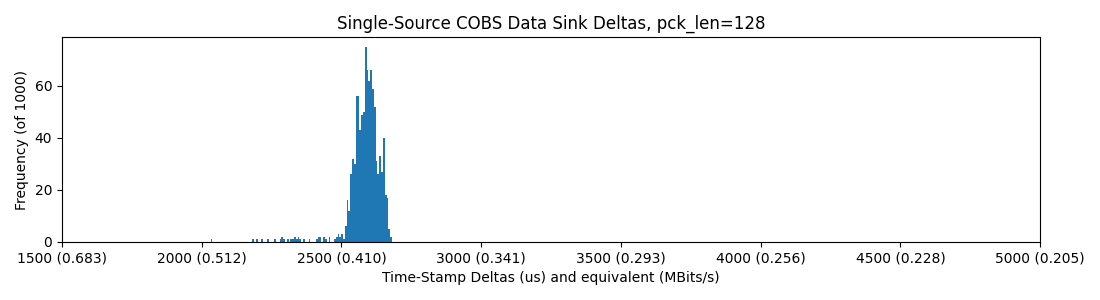
With a hub, note that some packets (in this sample of just 1000) land out of the normal distribution, up above 4500us per-packet-delay!
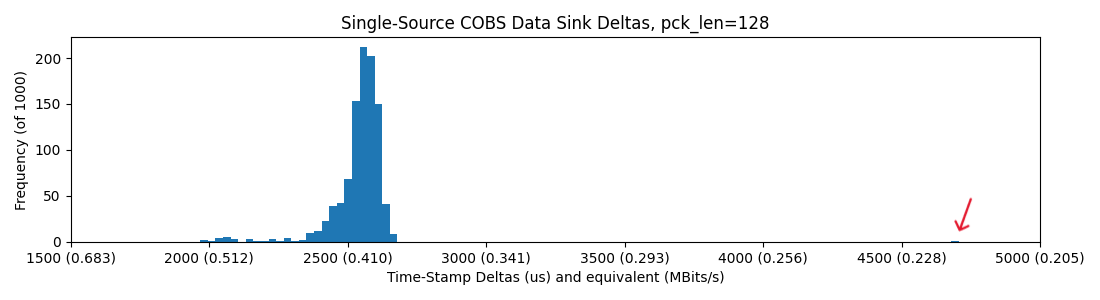
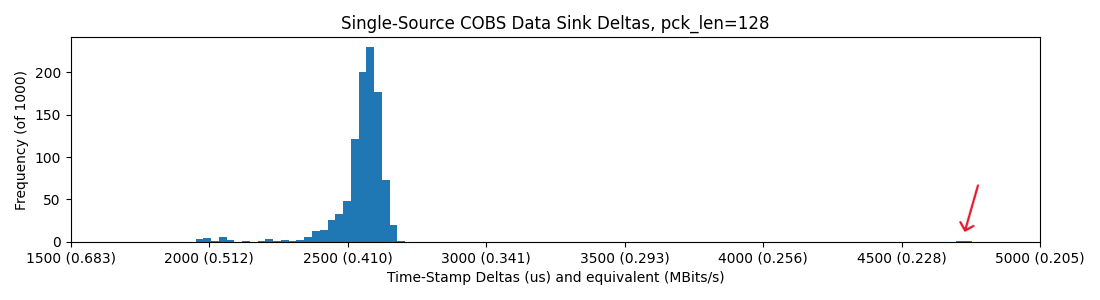
and four devices on the hub, where we catch a few more long-tail slow packets
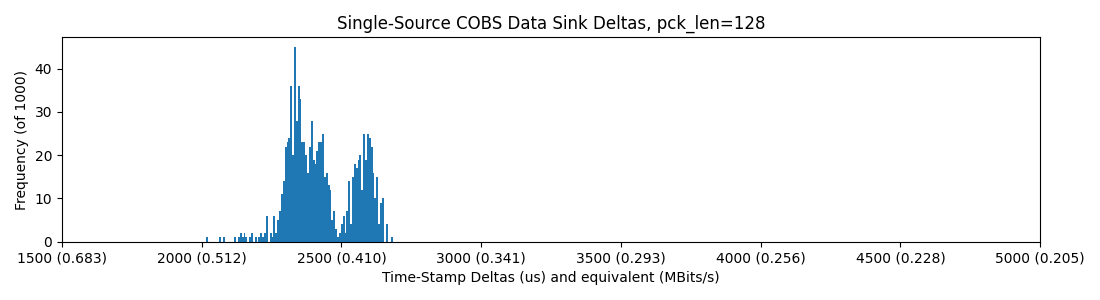
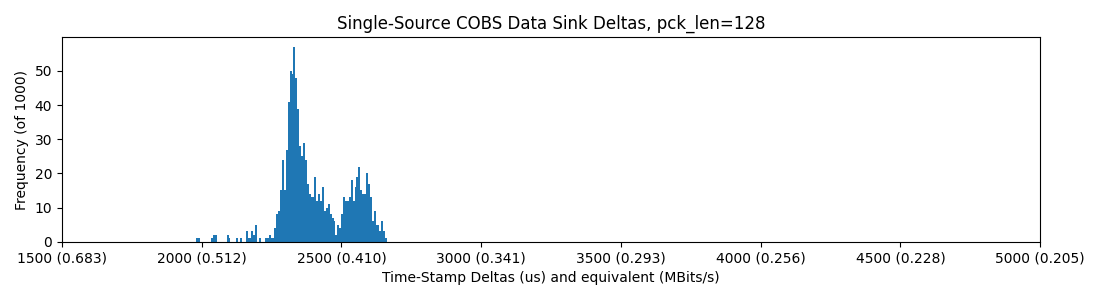
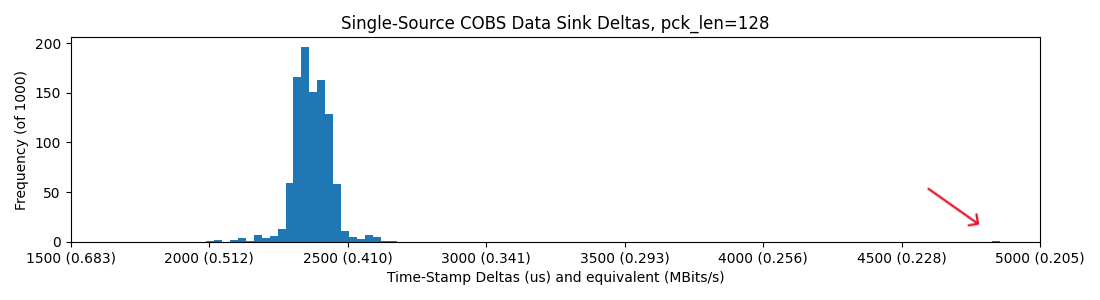
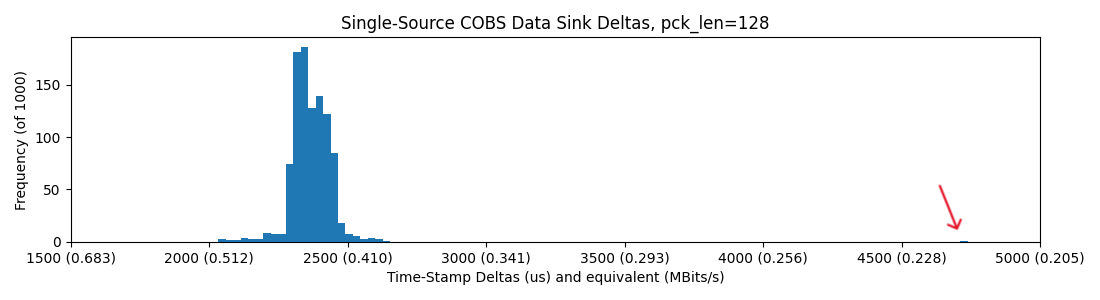
So, it seems basically that we are capped around 0.4MBit/sec in all of these scenarios, but introducing the hub sometimes casues packets to be delayed roughly 2x their normal delivery time. I figure that the hub is doing some switching / buffering that leads to this outcome...
Multi-Device, Asyncio
"under the hood" asyncio should have basically the same performance as the blocking codes above, but I should test a prototype, if no other reason than to understand the design patterns.


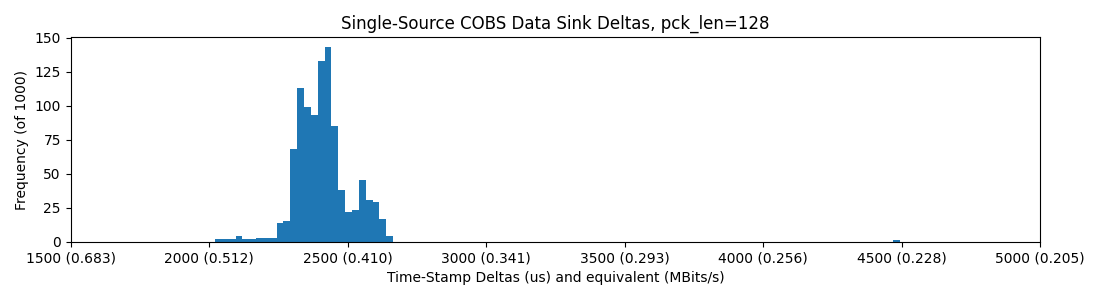
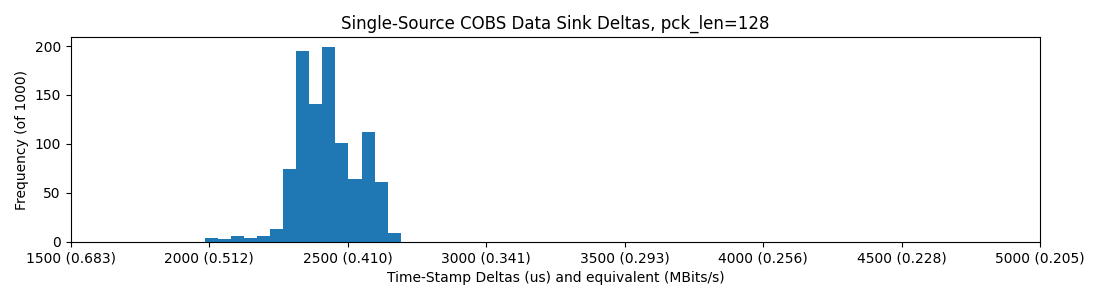
So, once again no difference here and we still see some stragglers on the third and fourth plots.
Multi-Device, Multiprocessing
To finish running through these tests, I want to try multi-processing which is true parallellism...
There's a nice natural alignment with this and the rest of these systems (which are all serialized-codes to begin with), so it might be that this approach just suits: it allows us to carry on doing comms-stuff (like not missing acks and timeouts) while users write potentially blocking-codes (which seems to be semi-common in python).
For future-architecture, my assumption is that I would do something like... one process does oversight, then we build one process per link layer, and probably even one per port, with user-application code going somewhere else.
So, I presume this will be a lot heavier-handed programming wise, I'll put a stake down before carrying on. Neil also reminded me that Urumbu has implemented multiprocessing, so I should take a look at that as well.