-
Amira Abdel-Rahman authoredAmira Abdel-Rahman authored

DICE for CNN
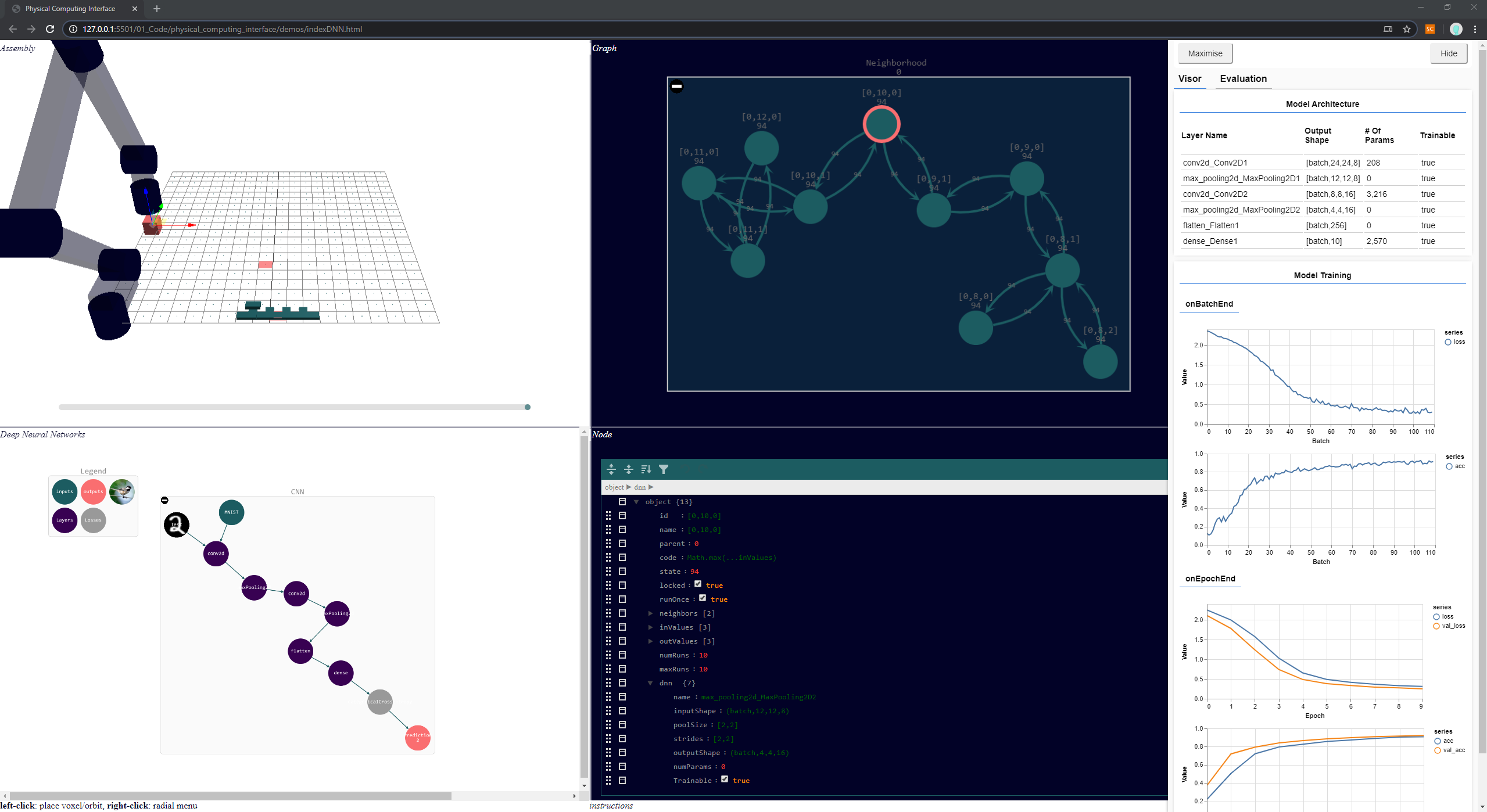
Another important application for DICE is to create reconfigurable computing systems for machine learning. Deep Neural Networks (DNNs) are currently used in countless applications, and through time, the models are becoming deeper and more sophisticated. In an attempt to benchmark and compare the training performance of variably sized and shaped DNNs on different hardware architectures (CPUs, GPUs or TPUs), its was concluded that there were no winners [1]. TPUs had the highest throughput and worked best with large batches, GPUs were more flexible for small problems and irregular computations, and CPUs were the most programmable and were the only ones to support larger models [1]. There is an increased need for accelerators and application-specific hardware in order to reduce data movement, one of the main bottlenecks of deep learning training, without compromising accuracy, throughput and cost [2].
Consequently, joint hardware/software design workflows are essential for developing a deep learning system, where spatial computing architectures are tailored to the depth and shape of the DNNs, as well as to the size of the training data. This will minimize the data movement and shared memory access, which dominates the energy consumption in traditional computing architectures.
As a first step to address this problem, a machine learning add-on was implemented as part of the integrated physical computing design tools. There, one is able to choose and add different kinds of DNN layers and specify their size, activation function, and parallelism strategy. The add-on also has a real-time graphical visualization of the training progress showing the updated accuracy of the model though time.
In order to benchmark and estimate the computing requirements for DICE to train DNNs, we chose AlexNet, a Convolutional Neural Network (CNN) that is widely used for benchmarking hardware as it was the first CNN to win the ImageNet challenge [3]. AlexNet consists of five convolutional (CONV) layers and three fully connected (FC) layers. For a 227x227 input image, it requires 61M weights and 724M multiply-and-accumulates (MACs). Similar to most DNN architectures, the FC layers have significantly more weights than CONV layers (58.6M vs 2.3M) and CONV layers are more computationally expensive than FC layers (666M MACs vs 58.6M MACs).
Assuming complete data parallelism, a number of challenges arise when naively trying to map AlexNet onto a DICE system that uses only one type of node (the SAMD51 processor prototype). Since each processor has only 256Kb of RAM, for FC layers, one might need up to 2300 nodes just to store the weights and perform the calculations, which will result in a communication overhead of more than 1600%. Therefore, specialized node types are required to efficiently map AlexNet, or any DNN, into a DICE architecture in an effort to minimize data movement, maximize number of parallel computations, and minimize the number of idle nodes. One is to design hierarchical memory allocation and access. Dedicated memory nodes could store data (filters, weights or input images) which is hierarchically broadcast based on the layer architecture. This enables temporal and spatial data reuse, where the data is read only once from the expensive memory and is sent to the small local cheap memory for reuse. Moreover, the number of weights stored and computation performed can be pruned by introducing specialized nodes that address the sparsity generated when using the `ReLU' as an activation function. For example, AlexNet's layers have around 19-63% sparsity. This has proven to reduce the energy cost by 96% using similar spatial architecture hardware [4]. If these changes were implemented, in addition to using the projected Summit MCU instead of the SAMD51, the computation speed will increase by 85x and the average communication overhead for FC layers will decrease to 33%.
Even though the performance of the first generation DICE demonstration for deep learning applications does not outperform current specialized HPC architectures, advances in Internet of Things and embodied computing require computation to be physically near sensors and data collection devices in order to minimize large data transfer. The modularity and ease of assembly of DICE will facilitates this system integration along with specialized robotic and electro-mechanical input and output modules for data collection, actuation and output visualization.
Furthermore, one key aspect of DICE modules is their reconfigurability; this means that in addition to changing the hardware modules to fit different types of networks, one can reconfigure the hardware itself as a system learns. Recent research in deep learning is developing dynamic DNNs that not only optimize their weights but also their structure, which means that the hardware should be optimized to match at different stages of the training. This reconfigurability will also be essential for online learning and probabilistic inference tasks where the computing architecture grows as more data are presented or more analysis is needed.
[1] Y. E. Wang, G.-Y. Wei, and D. Brooks, “Benchmarking tpu, gpu, and cpuplatforms for deep learning,”arXiv preprint arXiv:1907.10701, 2019.
[2] V. Sze, Y.-H. Chen, T.-J. Yang, and J. S. Emer, “Efficient processing of deep neural networks: A tutorial and survey,”Proceedings of the IEEE,vol. 105, no. 12, pp. 2295–2329, 2017.
[3] A. Krizhevsky, I. Sutskever, and G. E. Hinton, “Image net classification with deep convolutional neural networks,” inAdvances in neural information processing systems, 2012, pp. 1097–1105.
[4] Y.-H. Chen, T. Krishna, J. S. Emer, and V. Sze, “Eyeriss: An energy-efficient reconfigurable accelerator for deep convolutional neural net-works,”IEEE journal of solid-state circuits, vol. 52, no. 1, pp. 127–138,2016